Kube-apiserver 해부하기: 클러스터의 중앙 통제 센터 동작 원리
쿠버네티스 클러스터를 거대한 분산 시스템의 네트워크로 본다면, Kube-apiserver는 모든 신호를 수용하고 판단하여 명령을 내리는 '중앙 신경망'에 해당합니다. 쿠버네티스의 핵심 컴포넌트(Kubelet, Scheduler, Controller Manager 등)와 외부 사용자(kubectl, CI/CD 파이프라인, 대시보드)는 오직 Kube-apiserver하고만 통신하도록 설계되어 있습니다. 클러스터 내의 어떤 구성 요소도 Kube-apiserver를 거치지 않고서는 백엔드 저장소인 etcd에 직접 접근할 수 없습니다. 이 가이드에서는 Kube-apiserver가 내부적으로 어떻게 구성되어 있으며, 초당 수천 건씩 쏟아지는 API 요청을 어떤 정교한 파이프라인을 통해 처리하는지 심층적으로 해부합니다.
1. Kube-apiserver의 아키텍처적 핵심 원칙
Kube-apiserver는 본질적으로 대규모 트래픽 처리에 최적화된 RESTful API 서버이며, 시스템의 유연성과 안정성을 보장하기 위해 다음과 같은 핵심 원칙을 기반으로 설계되었습니다.
- 완벽한 무상태성 (Stateless Architecture): Kube-apiserver 프로세스 자체는 클러스터의 상태 데이터나 세션 정보를 메모리나 로컬 디스크에 영구적으로 보존하지 않습니다. 모든 영구적인 상태와 구성 데이터는 분산 키-값 저장소인 etcd에 전적으로 위임합니다. 이러한 무상태성 덕분에 트래픽 부하가 증가할 때 API 서버 인스턴스를 다중화하여 수평적으로 확장(Scale-out)하는 것이 매우 용이합니다.
- 보안과 무결성을 위한 단일 관문 (Single Point of Entry): 클러스터의 데이터 무결성을 유지하고 강력한 보안 통제를 적용하기 위한 유일한 통로입니다. 아무리 권한이 높은 관리자나 핵심 시스템 컴포넌트라도 반드시 이 관문을 통과하며 촘촘한 검증 파이프라인을 거쳐야 합니다.
- 선언적 명세 기반의 인터페이스: 사용자가 시스템에 원하는 최종 상태(Desired State)를 JSON 또는 YAML 형태로 제출하면, Kube-apiserver는 이를 쿠버네티스 내부의 고유한 GVK(Group, Version, Kind) 객체 모델로 변환하여 시스템이 이해하고 처리할 수 있도록 돕습니다.
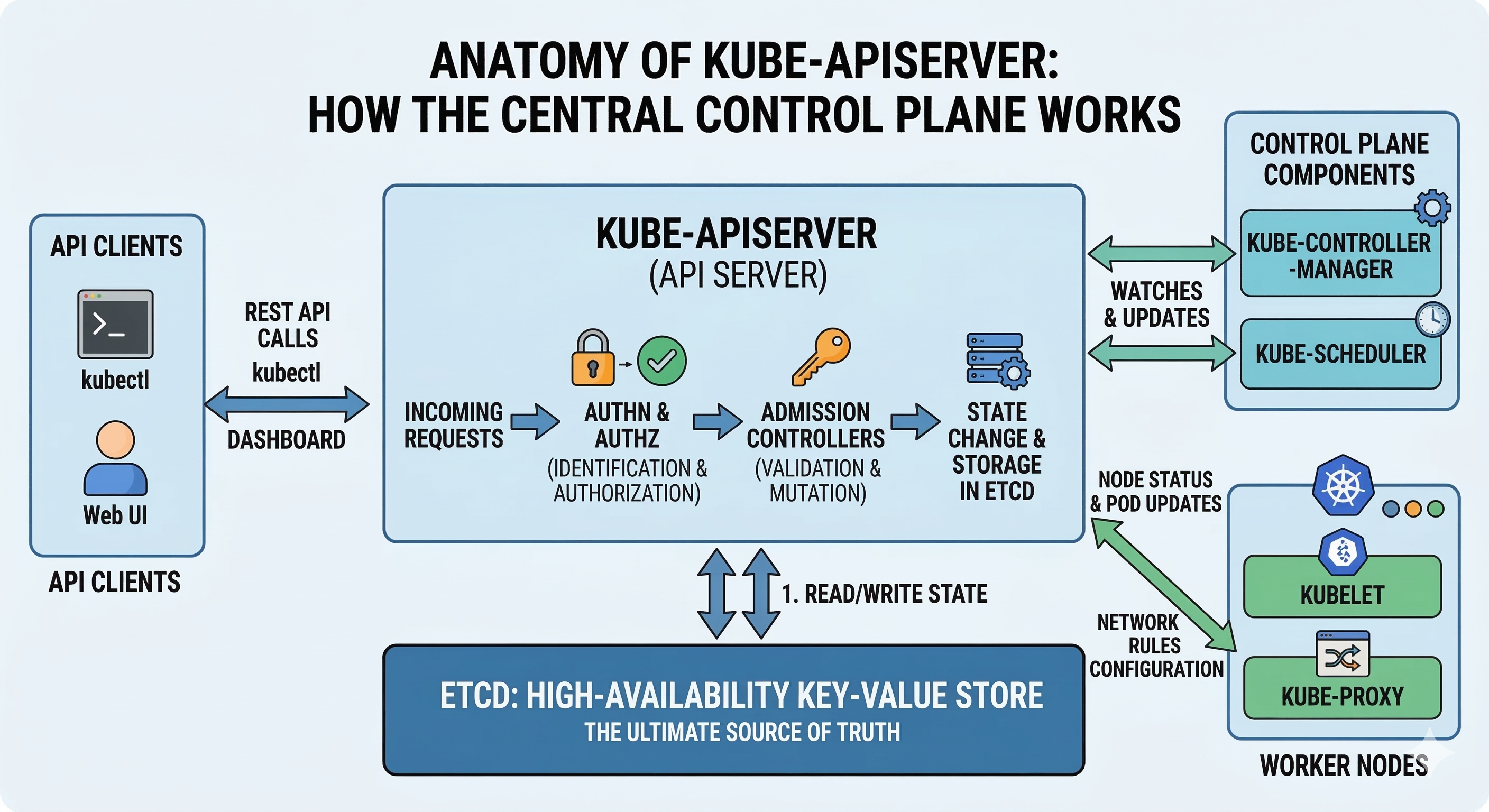
2. API 요청 처리 파이프라인 (The Request Processing Flow)
클라이언트가 kubectl apply -f deployment.yaml과 같은 명령어를 실행했을 때, Kube-apiserver 내부에서는 철저하게 모듈화된 파이프라인을 거쳐 해당 요청이 처리됩니다. 이 흐름은 크게 인증(Authentication) -> 인가(Authorization) -> 어드미션 컨트롤(Admission Control) -> etcd 저장의 4단계로 구성됩니다.
1단계: 인증 (Authentication) - "접근을 시도하는 주체는 누구인가?"
API 요청이 서버의 포트에 도달하면 가장 먼저 수행되는 작업은 요청을 보낸 주체의 신원을 식별하는 것입니다. Kube-apiserver는 자체적인 사용자 계정 데이터베이스를 가지지 않으며, 다양한 외부 인증 메커니즘을 체인 형태로 구성하여 확인합니다.
- X.509 클라이언트 인증서: 주로 컨트롤 플레인 컴포넌트(Kubelet, Kube-proxy 등) 간의 내부 통신이나 최고 관리자의 CLI 접근 시 사용되는 가장 강력한 인증 방식입니다.
- 베어러 토큰 (Bearer Tokens): Service Account 토큰을 통해 파드 내부에서 구동되는 애플리케이션이나 마이크로서비스가 API 서버에 시스템적으로 접근할 때 주로 사용됩니다.
- OIDC (OpenID Connect): 사내 Active Directory, Google Workspace, Okta 등 외부의 자격 증명 공급자(IdP)와 연동하여 실제 사람(Human User)을 인증하고 SSO(Single Sign-On)를 구현할 때 활용됩니다.
설정된 인증 모듈 중 하나라도 신원 확인에 성공하면, 요청은 해당 사용자의Username,UID,Groups정보가 담긴 컨텍스트 객체로 변환되어 다음 파이프라인으로 전달됩니다.
2단계: 인가 (Authorization) - "해당 작업을 수행할 적법한 권한이 있는가?"
사용자의 신원이 확인되면, 해당 사용자가 요청한 특정 리소스(예: Pods, Secrets, ConfigMaps)에 대해 특정한 행위(예: get, list, create, delete)를 실행할 권한이 있는지 엄격하게 검사합니다.
- RBAC (Role-Based Access Control): 현재 쿠버네티스의 표준이자 가장 널리 쓰이는 인가 방식입니다. 특정 네임스페이스에 국한된
Role이나 클러스터 전역에 적용되는ClusterRole을 정의하고, 이를 특정 사용자나 서비스 어카운트에RoleBinding또는ClusterRoleBinding으로 매핑하여 권한을 최소 권한의 원칙(Least Privilege)에 따라 세밀하게 제어합니다. - Webhook 인가: Open Policy Agent (OPA)와 같은 외부의 전문적인 정책 검증 엔진에 권한 검사 로직을 위임하는 방식입니다. 복잡한 기업용 보안 정책을 코드로 관리할 때 유용합니다.
요청이 인가 단계를 통과하지 못하면 Kube-apiserver는 즉각적으로HTTP 403 Forbidden상태 코드를 반환하고 파이프라인을 종료합니다.
3단계: 어드미션 컨트롤 (Admission Control) - "요청 데이터가 정책에 부합하며 안전한가?"
인증과 인가를 모두 통과한 데이터 생성, 수정, 삭제 요청은 마지막 보루인 어드미션 컨트롤러를 거칩니다. 이 단계는 단순한 권한 확인을 넘어, API 오브젝트의 구체적인 페이로드(Payload)를 검증하거나 시스템 정책에 맞게 자동으로 변형하는 역할을 수행합니다.
- Mutating Admission (변형 단계): 사용자가 요청한 오브젝트 데이터를 etcd에 저장하기 직전에 동적으로 수정하거나 기본값을 주입합니다. 예를 들어, 사용자가 컨테이너의 리소스 제한(Limits/Requests)을 명시하지 않았을 때
LimitRanger플러그인이 클러스터의 기본값을 삽입하거나, 서비스 메시(Istio 등) 환경에서 Envoy 프록시 사이드카 컨테이너를 파드 명세에 자동으로 밀어 넣는(Injection) 작업이 이곳에서 이루어집니다. - Validating Admission (검증 단계): 변형 단계를 거친 오브젝트의 데이터가 문법적, 의미론적 유효성을 완벽히 갖추었는지 최종적으로 검사합니다. 컨테이너가 시스템 루트(root) 권한으로 실행되려 하는지 차단하는
PodSecurity정책이나, 네임스페이스에 할당된 리소스 총량을 초과하는지 검사하는ResourceQuota플러그인이 대표적입니다.
플러그인 체인 중 단 하나라도 요청을 거부(Reject)하면 API 서버는 즉시 에러 응답을 반환합니다.
4단계: etcd 직렬화 저장 및 Watcher 이벤트 스트리밍
어드미션 컨트롤까지 완벽하게 통과한 데이터는 쿠버네티스 내부 포맷으로 직렬화되어 백엔드 스토리지인 etcd에 기록(Persist)됩니다. 데이터가 etcd의 디스크에 안전하게 동기화(fsync)된 이후에야 비로소 클라이언트에게 HTTP 2xx 성공 응답이 반환됩니다.
- 낙관적 동시성 제어 (Optimistic Concurrency Control): 대규모 분산 환경에서는 여러 컨트롤러가 동시에 동일한 오브젝트를 수정하려는 경쟁 상태(Race Condition)가 발생할 수 있습니다. Kube-apiserver는 리소스 메타데이터의
resourceVersion필드를 활용하여, 업데이트 충돌이 발생할 경우 나중에 들어온 요청을 기각하고 재시도를 유도함으로써 데이터의 정합성을 보장합니다. - Watch 메커니즘 (실시간 이벤트 스트리밍): API 서버 아키텍처의 가장 강력한 기능입니다. etcd에 리소스 생성, 수정, 삭제 등의 상태 변화가 발생하면 Kube-apiserver는 이를 즉각 감지합니다. 그리고 해당 리소스의 변화를 구독(Watch)하고 있는 Kubelet, Scheduler, Controller Manager 등에게 HTTP/2 기반의 지속 연결 스트림을 통해 이벤트를 실시간으로 밀어냅니다(Push). 이 메커니즘을 통해 쿠버네티스 특유의 끊임없는 조정 루프(Reconciliation Loop)가 지연 없이 원활하게 작동합니다.
3. 대규모 클러스터를 위한 성능 최적화와 확장성 메커니즘
수천 대의 노드와 수만 개의 파드가 쉴 새 없이 뿜어내는 API 트래픽의 병목을 방지하기 위해, Kube-apiserver는 엔터프라이즈급의 부하 제어 및 성능 최적화 기술을 내장하고 있습니다.
API Priority and Fairness (APF) - 지능형 트래픽 셰이핑
과거에는 단순한 최대 동시 요청 수 제한(Max-in-flight) 메커니즘만 존재했습니다. 이로 인해 중요도가 낮은 대규모 로그 조회나 외부 CI 툴의 스크래핑 요청이 폭주할 경우, 클러스터의 생존에 직결되는 핵심 컴포넌트(노드 헬스 체크 업데이트, 파드 스케줄링)의 트래픽까지 함께 병목 현상을 겪는 심각한 문제가 있었습니다.
APF 메커니즘은 유입되는 모든 API 요청을 분석하여 FlowSchema에 따라 다수의 우선순위 레벨(Priority Levels)과 대기열(Queues)로 세분화합니다. 시스템 유지에 필수적인 컨트롤 플레인 트래픽은 최상위 대기열에서 즉시 처리되도록 보장하고, 일반 사용자의 무거운 List 요청은 하위 대기열에 배치하여 지연시키거나 기각(Drop)함으로써 API 서버의 과부하로 인한 클러스터 전체의 연쇄적인 붕괴(Cascading Failure)를 완벽하게 차단합니다.
In-Memory Watch Cache 아키텍처
클러스터 내부의 수많은 컨트롤러들은 자신의 작업을 수행하기 위해 주기적으로 특정 리소스의 전체 목록(List)을 조회합니다. 이러한 요청이 들어올 때마다 API 서버가 매번 etcd에 직접 쿼리를 수행한다면 etcd의 디스크 I/O와 CPU 리소스는 순식간에 고갈될 것입니다.
이를 방지하기 위해 Kube-apiserver는 로컬 메모리 내부에 etcd 데이터의 복제본인 Watch Cache를 유지합니다. 클라이언트가 API 요청 시 명시적으로 최신 데이터를 etcd에서 직접 읽어오도록 강제(ResourceVersion=0 또는 미지정 등의 조건)하지 않는 한, API 서버는 내부 메모리의 캐시 데이터를 즉시 반환하여 응답 지연 시간(Latency)을 마이크로초 단위로 단축하고 etcd를 보호합니다.
API Aggregation Layer (확장형 아키텍처)
쿠버네티스의 기능이 방대해짐에 따라 모든 기능을 코어 Kube-apiserver 바이너리에 포함시키는 것은 비효율적이 되었습니다. API Aggregation Layer는 사용자가 직접 개발한 커스텀 API 서버(예: Metrics Server, 커스텀 리소스 컨트롤러)를 메인 Kube-apiserver 뒤에 연결할 수 있게 해주는 프록시 메커니즘입니다. 클라이언트는 단일 진입점인 Kube-apiserver로 요청을 보내지만, Kube-apiserver는 URL 경로를 분석하여 커스텀 리소스에 대한 요청을 백엔드의 확장 API 서버로 투명하게 라우팅합니다.
HA (고가용성) 토폴로지 구성
단일 실패 지점(SPOF)을 제거하고 무중단 운영을 보장하기 위해 프로덕션 환경의 Kube-apiserver는 최소 3대 이상의 물리적으로 분리된 마스터 노드(또는 컨트롤 플레인 인스턴스)에 다중 배포됩니다. 각 API 서버 인스턴스 앞단에는 로드밸런서(L4 스위치, HAProxy, NGINX 등)가 배치되어 들어오는 트래픽을 라운드 로빈(Round Robin) 방식으로 고르게 분산시킵니다. API 서버 자체는 완벽히 무상태이므로 노드 증설에 따라 선형적인 트래픽 처리량(Throughput) 증가를 얻을 수 있습니다.
4. REST 매핑과 GVK (Group, Version, Kind) 객체 모델
Kube-apiserver는 하위 호환성을 엄격하게 유지하면서도 끊임없이 새로운 아키텍처와 기능을 수용하기 위해 고도화된 API 버전 관리 체계를 사용합니다. 모든 쿠버네티스 리소스는 GVK 모델로 식별됩니다.
- Group (API 그룹): 목적이 유사한 연관 리소스들의 논리적 컬렉션입니다. (예:
apps,batch,networking.k8s.io, 코어 그룹은"") - Version (버전): 해당 API 설계의 성숙도와 안정성을 나타냅니다. (예: 실험적인
v1alpha1, 기능이 확정된v1beta1, 프로덕션 레벨의v1) - Kind (오브젝트 종류): 조작하고자 하는 실제 리소스의 타입입니다. (예:
Deployment,DaemonSet,Pod)
클라이언트가 HTTP URL 경로(/apis/apps/v1/namespaces/default/deployments)를 통해 특정 버전으로 요청을 보내면, Kube-apiserver 내부의 REST Mapper가 이를 파싱합니다. 중요한 점은 사용자가 구버전인 v1beta1으로 요청을 보내거나 신버전인 v1으로 요청을 보내더라도, Kube-apiserver 내부에서는 이를 공통된 스키마인 내부 버전(Internal Version)으로 자동 변환하여 비즈니스 로직을 처리하고 etcd에 단일화된 형태로 저장한다는 것입니다. 이를 통해 쿠버네티스는 복잡한 버전 파편화 없이 안정적으로 시스템을 업그레이드할 수 있습니다.
'1. K8s Core & Architecture > 1.1. 컨트롤 플레인 (Control Plane) 심층 분석' 카테고리의 다른 글
| etcd의 Watcher 메커니즘과 Kube-apiserver의 실시간 동기화 원리 (0) | 2026.03.16 |
|---|---|
| etcd 고가용성(HA) 클러스터 구성과 백업/복구 베스트 프랙티스 (0) | 2026.03.15 |
| etcd 심층 분석: 쿠버네티스의 모든 상태 데이터는 어떻게 저장되는가? (0) | 2026.03.15 |
| API 서버의 요청 처리 흐름: Authentication부터 Admission Control까지 (1) | 2026.03.15 |
| 쿠버네티스 아키텍처의 큰 그림: 전체 컴포넌트 구조 이해하기 (0) | 2026.03.14 |



