쿠버네티스 아키텍처의 큰 그림: 전체 컴포넌트 구조 이해하기
쿠버네티스(Kubernetes)는 복잡한 컨테이너화된 애플리케이션을 자동으로 배포, 확장, 관리해주는 강력한 클라우드 네이티브 오케스트레이션 시스템입니다. 이 거대한 분산 시스템이 어떻게 수천 개의 컨테이너를 안정적으로 운영하고 장애를 스스로 복구할 수 있는지 이해하려면, 전체 아키텍처의 밑그림을 그릴 줄 알아야 합니다. 쿠버네티스 클러스터는 크게 클러스터의 두뇌 역할을 하며 전체 상태를 통제하는 '컨트롤 플레인(Control Plane)'과 실제 애플리케이션 컨테이너가 실행되는 작업 공간인 '워커 노드(Worker Node)' 두 가지 핵심 파트로 나뉩니다.
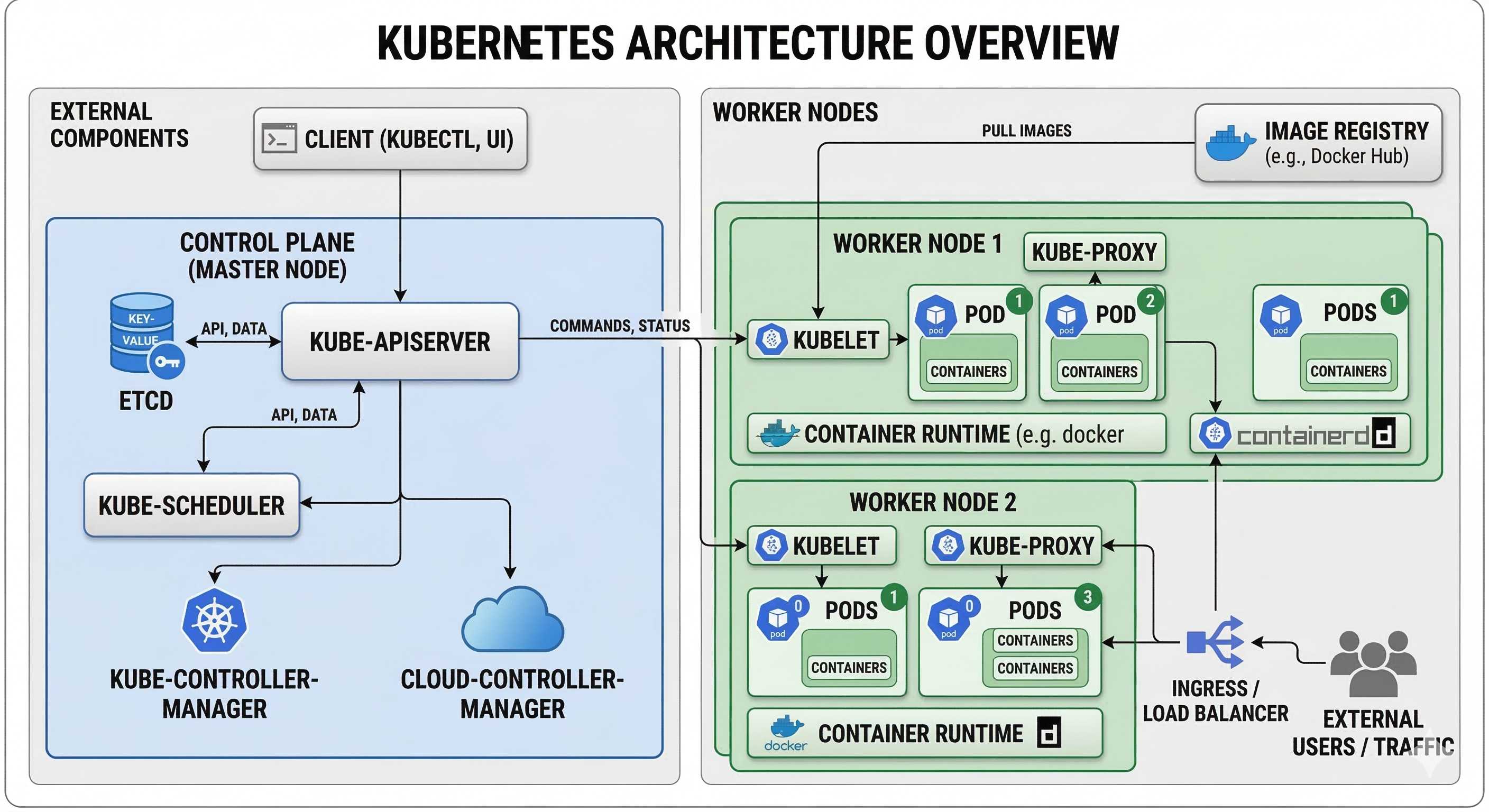
1. 쿠버네티스 아키텍처의 핵심 철학: 선언적 상태 유지 (Declarative State)
쿠버네티스 아키텍처를 관통하는 가장 중요한 핵심 개념은 '선언적 상태'와 '조정 루프(Reconciliation Loop)'입니다. 사용자는 시스템에 절차적인 명령(예: "A 컨테이너를 3개 실행하고 로드밸런서를 붙여라")을 내리지 않습니다. 대신, YAML이나 JSON 매니페스트를 통해 원하는 최종 상태(Desired State)를 선언합니다. 쿠버네티스의 모든 컴포넌트는 현재 상태(Current State)를 지속적으로 감시하며, 사용자가 선언한 상태와 불일치하는 부분이 발견되면 이를 일치시키기 위해 스스로 끊임없이 동작합니다. 이러한 철학이 전체 컴포넌트 간의 분산 아키텍처를 가능하게 합니다.
2. 컨트롤 플레인 (Control Plane): 클러스터의 두뇌
컨트롤 플레인은 클러스터 전체의 전반적인 결정을 내리고 클러스터 이벤트를 감지하고 반응하는 역할을 합니다. 프로덕션 환경에서는 장애를 대비한 고가용성(HA)을 보장하기 위해 여러 대의 마스터 노드에 각 컴포넌트가 다중화되어 배포됩니다.
2.1. kube-apiserver (API 서버)
API 서버는 쿠버네티스 컨트롤 플레인의 프론트엔드이자 클러스터의 중앙 통신 허브입니다. 클러스터 내부의 모든 컴포넌트(kubelet, scheduler 등)는 물론 외부 사용자(kubectl, CI/CD 시스템)는 오직 API 서버하고만 직접 통신합니다.
API 서버는 사용자로부터 들어온 REST API 요청에 대해 인증(Authentication)과 인가(Authorization, 주로 RBAC)를 수행하고, 어드미션 컨트롤러(Admission Controller)를 통해 요청 데이터를 검증하거나 기본값을 주입합니다. 이후 처리된 클러스터의 상태 데이터를 분산 저장소인 etcd에 기록하거나 읽어오는 유일한 컴포넌트입니다. 수많은 컴포넌트의 동시다발적인 트래픽을 감당하기 위해 무상태(Stateless)로 설계되어 수평적 확장이 용이합니다.
2.2. etcd (분산 키-값 저장소)
etcd는 고가용성을 보장하는 강력한 일관성의 분산 키-값(Key-Value) 저장소입니다. 쿠버네티스 클러스터의 모든 상태 데이터, 리소스 명세, 시크릿(Secret), 구성 데이터가 보관되는 단일 진실의 공급원(Single Source of Truth)입니다.
etcd 내부적으로는 bbolt라는 스토리지 엔진과 다중 버전 동시성 제어(MVCC)를 사용하여 데이터를 저장하며, 분산 노드 간의 데이터 일관성을 위해 뗏목(Raft) 합의 알고리즘을 사용합니다. 디스크 I/O 속도(특히 fsync 지연 시간)가 전체 클러스터 성능에 직결되므로 반드시 고성능 SSD를 사용하여 구성해야 하며, 클러스터 장애 시 복구를 위한 백업 1순위 타겟입니다.
2.3. kube-scheduler (스케줄러)
API 서버를 통해 새롭게 생성되었지만 아직 어느 노드에서 실행될지 결정되지 않은(Pending 상태) 파드를 감지하고, 해당 파드가 실행될 최적의 워커 노드를 찾아 할당(Binding)하는 역할을 합니다.
스케줄러는 단순히 무작위로 파드를 배치하지 않습니다. 필터링(Filtering) 단계를 통해 파드가 요구하는 CPU/메모리 리소스를 충족하는지, 포트 충돌은 없는지, 테인트(Taint)를 수용(Toleration)할 수 있는지 등 자격 미달인 노드를 걸러냅니다. 이후 스코어링(Scoring) 단계를 통해 남은 노드들을 대상으로 데이터 지역성, 노드 어피니티(Affinity), 파드 분산 제약 조건 등을 수치화하여 가장 높은 점수를 얻은 노드에 파드를 배치합니다.
2.4. kube-controller-manager (컨트롤러 매니저)
다양한 컨트롤러 프로세스들을 단일 바이너리로 컴파일하여 실행하는 배경 데몬입니다. 컨트롤러는 앞서 언급한 '조정 루프'를 실행하는 주체로, API 서버를 통해 클러스터의 상태를 지속적으로 관찰(Watch)합니다.
여기에는 노드의 응답이 끊기면 파드를 다른 곳으로 옮기는 노드 컨트롤러(Node Controller), 선언된 파드의 개수(Replica)를 정확히 유지하는 레플리카셋 컨트롤러(ReplicaSet Controller), 파드와 서비스를 네트워크 단위로 연결하는 엔드포인트 컨트롤러(Endpoint Controller), 임시 토큰과 계정을 관리하는 서비스 어카운트 컨트롤러 등이 모두 포함되어 있습니다.
2.5. cloud-controller-manager (클라우드 컨트롤러 매니저)
클러스터를 특정 클라우드 벤더(AWS, GCP, Azure 등)의 인프라 API와 연동하는 컴포넌트입니다. 쿠버네티스 내부 로직과 클라우드 종속적인 코드를 분리하기 위해 도입되었습니다. 사용자가 로드밸런서 타입의 서비스를 생성하면 클라우드 로드밸런서를 프로비저닝하고, 클라우드 인스턴스가 삭제되면 쿠버네티스 노드 목록에서도 해당 노드를 정리하는 등 퍼블릭 클라우드 자원의 라이프사이클을 쿠버네티스와 동기화합니다.
3. 워커 노드 (Worker Node): 실질적인 작업 공간
컨트롤 플레인이 클러스터를 지휘하는 통제실이라면, 워커 노드는 실제 컨테이너화된 애플리케이션 파드가 배포되고 사용자 트래픽을 처리하는 물리적 기계 또는 가상 머신입니다. 각 노드에는 API 서버와 통신하고 컨테이너를 띄우기 위한 핵심 에이전트들이 설치됩니다.
3.1. kubelet (큐블릿)
각 워커 노드에서 실행되는 가장 핵심적인 캡틴(Captain) 에이전트입니다. kubelet은 컨트롤 플레인의 API 서버를 주시하며 자신에게 할당된 파드의 명세(PodSpec)를 확인합니다.
새로운 파드가 할당되면 컨테이너 런타임 인터페이스(CRI)를 통해 런타임에게 컨테이너의 생성을 지시합니다. PLEG(Pod Lifecycle Event Generator) 메커니즘을 통해 실행 중인 컨테이너의 상태를 모니터링하고, 프로브(Liveness/Readiness/Startup Probe)를 실행하여 헬스 체크를 담당합니다. 또한 컨테이너가 소비하는 자원을 리눅스 cgroup과 연동하여 제한하며, 이 모든 노드의 상태와 리소스 사용량을 API 서버로 지속적으로 보고합니다.
3.2. kube-proxy (큐브 프록시)
각 노드에서 실행되는 네트워크 프록시이자 라우터로, 쿠버네티스의 서비스(Service) 네트워킹 철학을 구현하는 핵심 요소입니다.
클러스터 내부 또는 외부에서 들어오는 네트워크 트래픽을 적절한 파드로 라우팅하고 로드밸런싱합니다. 최신 환경에서는 주로 리눅스 커널의 iptables나 IPVS(IP Virtual Server) 기술을 조작하여, 서비스가 가지는 가상의 IP(ClusterIP)로 요청이 들어올 때 이를 네트워크 패킷 레벨에서 가로채어 실제 살아있는 파드의 IP 주소로 목적지를 변환(DNAT)하는 역할을 수행합니다.
3.3. 컨테이너 런타임 (Container Runtime)
실제로 파드 내부의 컨테이너를 실행하고 격리하는 하위 소프트웨어입니다. 쿠버네티스는 CRI(Container Runtime Interface)라는 표준 인터페이스를 제공하여 런타임 구현체를 플러그인처럼 교체할 수 있도록 설계했습니다.
과거에는 Docker가 사용되었으나 현재는 OCI(Open Container Initiative) 표준을 준수하는 containerd 또는 CRI-O가 주로 사용됩니다. kubelet의 명령을 받아 레지스트리에서 이미지를 풀링(Image Pulling)하고, 리눅스 네임스페이스(Namespaces)를 통해 네트워크와 프로세스를 격리하며, 애플리케이션 프로세스를 가동합니다.
3.4. 애드온 (Add-ons)
엄밀히 말해 쿠버네티스 코어 바이너리는 아니지만, 클러스터가 제 기능을 하기 위해 워커 노드에 파드 형태로 실행되는 필수 인프라 서비스들입니다.
- DNS (CoreDNS): 클러스터 내부의 서비스 디스커버리를 위해 IP 대신 도메인 이름으로 통신할 수 있게 해주는 네임 서버입니다.
- CNI (Container Network Interface) 플러그인: 파드 간에 고유한 IP를 할당하고 노드 간 네트워크 라우팅(Overlay 네트워크 등)을 구성하는 서드파티 네트워크 솔루션입니다. (예: Calico, Cilium, Flannel)
4. 컴포넌트 간의 상호작용: 파드 배포 전체 흐름
독립적으로 보이는 이 컴포넌트들이 어떻게 유기적으로 동작하는지, 파드 생성(Pod Creation) 과정을 시간순으로 추적해보면 아키텍처의 큰 그림이 완성됩니다.
- 사용자 요청: 사용자가
kubectl apply를 통해 웹 서버 파드 생성을 요청하면, 이 트래픽은 kube-apiserver로 전달됩니다. - 상태 저장: kube-apiserver는 요청의 권한을 검증한 뒤, 해당 파드의 명세(현재 노드 할당 안됨 상태)를 etcd에 기록하고 성공을 반환합니다.
- 스케줄링: kube-scheduler는 API 서버를 통해 새로운 파드가 생성된 것을 감지하고, 클러스터 내 노드들의 자원을 분석하여 최적의 워커 노드 1개를 선택합니다. 그리고 이 바인딩 정보를 API 서버에 전달하여 etcd를 업데이트합니다.
- 명령 하달: 파드가 할당된 노드의 kubelet은 API 서버를 감지하고 있다가 자기 노드에 새 작업이 떨어졌음을 인지합니다.
- 네트워크 및 스토리지 구성: kubelet은 CNI 플러그인을 호출하여 파드의 네트워크 인터페이스를 세팅하고, 필요시 볼륨 스토리지(CSI)를 마운트합니다.
- 컨테이너 실행: kubelet이 컨테이너 런타임(containerd)에게 컨테이너 구동을 명령하면, 이미지를 다운받아 최종적으로 애플리케이션 프로세스가 시작됩니다.
- 최종 상태 보고: 파드가 정상적으로 구동되면 kubelet은 "Running" 상태를 API 서버에 보고하고, 이 최종 정보가 etcd에 업데이트됨으로써 전체 조정 루프가 완료됩니다.
이처럼 쿠버네티스 아키텍처는 API 서버를 중앙에 둔 완벽한 마이크로서비스 구조의 집합체입니다. 각 컴포넌트는 자신이 맡은 도메인에만 집중하며, 서로 직접 통신하지 않고 오직 API 서버를 통한 비동기 상태 감지(Watch) 방식으로 상호작용합니다. 이러한 철저한 역할 분리와 선언적 상태 유지 메커니즘이 바로 쿠버네티스가 어떠한 인프라 환경에서도 유연하게 확장하고 장애를 견뎌낼 수 있는 근본적인 원동력입니다.
'1. K8s Core & Architecture > 1.1. 컨트롤 플레인 (Control Plane) 심층 분석' 카테고리의 다른 글
| etcd의 Watcher 메커니즘과 Kube-apiserver의 실시간 동기화 원리 (0) | 2026.03.16 |
|---|---|
| etcd 고가용성(HA) 클러스터 구성과 백업/복구 베스트 프랙티스 (0) | 2026.03.15 |
| etcd 심층 분석: 쿠버네티스의 모든 상태 데이터는 어떻게 저장되는가? (0) | 2026.03.15 |
| API 서버의 요청 처리 흐름: Authentication부터 Admission Control까지 (1) | 2026.03.15 |
| Kube-apiserver 해부하기: 클러스터의 중앙 통제 센터 동작 원리 (0) | 2026.03.15 |



